My question is about Huffman codes. Consider a random variable $X$ which takes $6$ values $A, B, C, D, E, F$ with probabilities $(0.5, 0.25, 0.1, 0.05, 0.05, 0.05)$ respectively. We want to construct a binary Huffman code for it. Here in the solution it has constructed these codes:
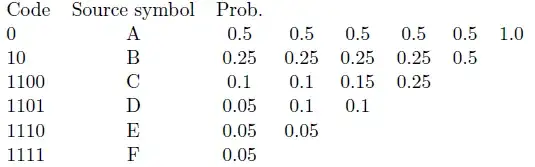
But I solved it myself and find different codes:

My codes are these: $(A=0, B=10, C=111, D=1101, E=11000, F=11001)$
Although average length of both codes are the same and is equal to 2, the codes are different(for example in the first one, the length of C is 4, but in the second one, its length is 3). I wanted to know why this difference happens and which one is correct and standard?