Update
Thought my original answer would give another view into why it's "just a problem with precision," in Silvia's words, that would make it easy to see why. I also thought it showed that approaches with ND[] and other local methods for estimating derivative would be unable to achieve the OP's goals. Apparently I was wrong: Either something I wrote is incorrect or it's not easy to see. So I will add a few points.
Let me point a well-known phenomenon: Differentiation magnifies noise. So inexact data will lead to increasingly inaccurate derivatives.
While it's true that mathematically derivatives are determined by local function values, numerically it's a bad idea to make the step size too small, since differentiation essentially magnifies the error by the reciprocal of the step size.
Actually for an analytic function, that is, represented by a power series, over a large domain, it can turn out to be better to increase the range of the sampling (up to a point).
Pseudospectral sampling, such as in my original answer, is nice and shows the point at which the maximum precision is achieved; but we can even use uniform sampling to make a good estimate of the derivative in the center of the interval.
If the domain is finite and the noise/round-off fixed, then there is a limit to the order of the derivative that can be accurately approximated.
For an example, I show off NDSolve`FiniteDifferenceDerivative, which has not yet shown up in an answer, on the analytic function $e^x+2 \cos x$. I use a uniform grid 33 points (interpolation order 32). The scale s sets the interval for the sample to $[-s,s]$. The table shows the difference from the exact derivative ${d^k \over dx^k} (e^x+2 \cos x)$, $k=0,1,\dots,15$. The exact derivative is shown in the last column. Large error values are colored. One can see from the table that the error increases with the order of the derivative, but more significantly, it decreases as the scale/grid-space increases up to a point.

nn = 32; (* order of interpolation *)
ff[x_] := Exp[x] + 2 Cos[x];
Table[
If[s =!= Infinity,
grid = Range[-N@nn, nn, 2]/nn*s;
fvals = ff[grid];
];
Table[
If[k == 0,
(* header *)
Row[{"s .= ", s}],
If[s === Infinity,
(* exact value *)
D[ff[x], {x, k}] /. x -> 0.,
(* error of approximation *)
NDSolve`FiniteDifferenceDerivative[k, grid, fvals,
DifferenceOrder -> nn - k + 1][[1 + nn/2]] -
(D[ff[x], {x, k}] /. x -> 0.) /.
{d_ /; Abs[d] >= 10 :>
Style[d, Blend[{Darker@Red, Magenta}]],
d_ /; Abs[d] >= 1/1000 :> Style[d, Darker@Green]}
]
],
{k, 0, 15}],
{s, 2^Range[-2, 5]~Join~{Infinity}}] // Transpose //
Grid[#, Alignment -> "."] & // ScientificForm[#, 2] &
Original answer
I believe the growth in $c_i$ is due to the effect of noise ($\epsilon \approx 10^{-10}$). One also might consider, given $-0.5<x<0.5$, the basis functions $\phi_n(x) = (2x)^n$ instead of the power basis $x^n$, which is making the coefficients $c_i$ seem larger than their effect. The coefficients with respect to $\phi_n$ would be $c_n/2^n$.
As an example, here a Chebyshev series of a noisy function:
ff = Function[x, Sin[x] + Exp[2 x]];
nn = 32; (* degree of approximation *)
xx = Sin[Pi/2 Range[1. nn, -1. nn, -2.]/nn]/2;
SeedRandom[0];
noise = RandomReal[10^-10 {-1, 1}, nn + 1];
yy = ff[xx] + noise;
cc = Sqrt[2/nn] FourierDCT[yy, 1];
cc[[{-1, 1}]] /= 2;
ListPlot[RealExponent@cc, GridLines -> {{11}, None},
DataRange -> {0, nn}]
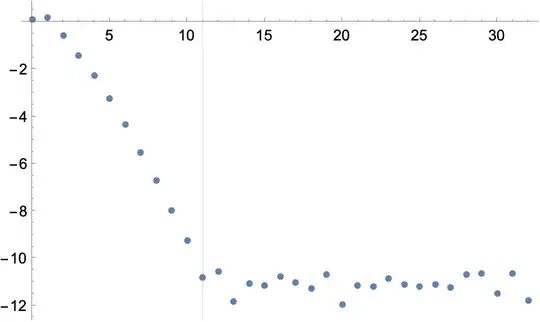
In this example, the maximum achievable precision is obtain with degree 11. One should expect the Taylor coefficients to increase after this point.
(*https://mathematica.stackexchange.com/a/13681/4999*)
chebeval[cof_?VectorQ, x_] :=
Module[{m = Length[cof], j, u, v, w}, w = v = 0;
Do[u = 2 x v - w + cof[[j]];
w = v; v = u, {j, m, 2, -1}];
Expand[x v - w + First[cof]]]
chebeval[cc[[;; 17]], 2 x]
Series[ff[x], {x, 0, 16}] // Normal // N
(* polynomials *)
ListPlot[RealExponent@{
CoefficientList[chebeval[cc[[;; 17]], 2 x], x],
CoefficientList[Series[ff[x], {x, 0, 16}] // Normal // N, x]
},
PlotLabel -> "Log[coefficient]", DataRange -> {0, 16}]
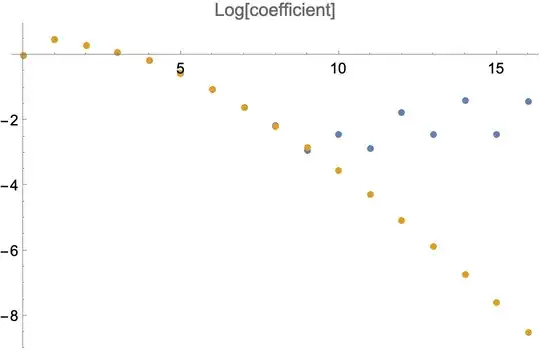
The separation starts a little earlier, at degree $10$.

sqrt(x^2)? – Daniel Lichtblau Aug 17 '22 at 08:49