Here are a few ways, each of which operates upon the individual component associations. In the following discussion, recall that when a key name is not a valid symbol we can write, for example, #["col_name"] instead of #col.
We can explicitly construct a new association that includes all of the old columns and adds a new one:
ds[All, <| "col1"->"col1", "col2"->"col2", "col3"->(#col1 + #col2&) |>]
(* col1 col2 col3
1 2 3
3 4 7
5 6 11
*)
This has the disadvantage that we have to list all of the existing columns. To avoid this, we can use Append:
ds[All, Append[#, "col3" -> #col1 + #col2]&]
(* col1 col2 col3
1 2 3
3 4 7
5 6 11
*)
Should we wish to add multiple computed columns, we can use Join:
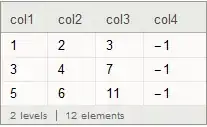
ds[All, # ~Join~ <| "col3" -> #col1 + #col2, "col4" -> #col1 * #col2 |> &]
(* col1 col2 col3 col4
1 2 3 2
3 4 7 12
5 6 11 30
*)
By exploiting the fact that <| ... |> syntax can be nested:
<| <| "a" -> 1 |>, "b" -> 2 |>
(* <| "a" -> 1, "b" -> 2 |> *)
... we can append columns to the dataset's associations using a shorter form:
ds[All, <| #, "col3" -> #col1 + #col2, "col4" -> #col1*#col2 |> &]
(* col1 col2 col3 col4
1 2 3 2
3 4 7 12
5 6 11 30
*)
2017 Update: It has been observed that the shorter form is not explictly mentioned in the documentation for Association (as of V11.1, see comments 1 and 2 for example). The documentation does mention that lists are "flattened out":
<| {"x" -> 1, "y" -> 2} |>
(* <| "x" -> 1, "y" -> 2 |> *)
... and that all but the last occurrence of repeated keys are ignored:
<| {"x" -> 1, "y" -> 1}, "y" -> 2 |>
(* <| "x" -> 1, "y" -> 2 |> *)
The documentation also frequently says that associations can be used in place of lists in many functions. It should come as no surprise that Association itself allows us to use an association in place of a list:
<| <| "x" -> 1, "y" -> 2 |> |>
(* <| "x" -> 1, "y" -> 2 |> *)
<| <| "x" -> 1, "y" -> 1 |>, "y" -> 2 |>
(* <| "x" -> 1, "y" -> 2 |> *)
This last expression is the "shorter form" from above.
Notwithstanding that the documentation strongly suggests that the short form is valid, I agree with commentators that it would be better if the documentation explicitly discussed the construction.