For version 10 you might use:
interval ~Select~ DuplicateFreeQ
Interval[{2894659200, 2894832000}, {2895177600, 2895350400}]
For other versions alternatives to DeleteCases include:
Select[interval, UnsameQ @@ # &]
Pick[#, UnsameQ @@@ #] & @ interval
Benchmarks
As requested:
generate[n_] :=
Sort @ RandomInteger[n, ⌊.7n⌋] ~Partition~ 2 // Apply[Interval];
f1 = DeleteCases[{x_, x_}];
f2 = Select[DuplicateFreeQ];
f3 = Select[UnsameQ @@ # &];
f4 = Pick[#, UnsameQ @@@ #] &;
f5 = # /. {x_, x_} :> Sequence[] &;
Needs["GeneralUtilities`"]
BenchmarkPlot[{f1, f2, f3, f4, f5}, generate, 2^Range[7, 16], "IncludeFits" -> True]
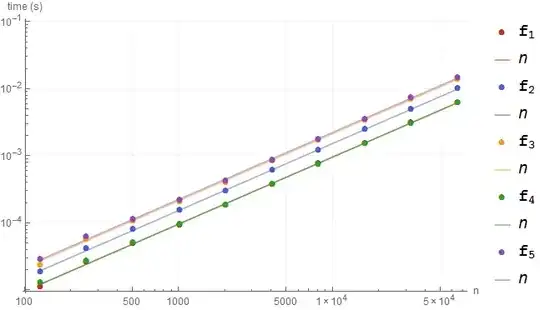
The lines are hard to see here but:
f1 and f4 are the winners with nearly identical timingsf3 and f5 are the slowestf2 is in the middle- All methods have the same complexity, unsurprisingly
If speed is the goal f5 can be improved by using Replace:
f6 = Replace[#, {x_, x_} :> Sequence[], {1}] &;
BenchmarkPlot[{f1, f5, f6}, generate, 2^Range[7, 16], "IncludeFits" -> True]
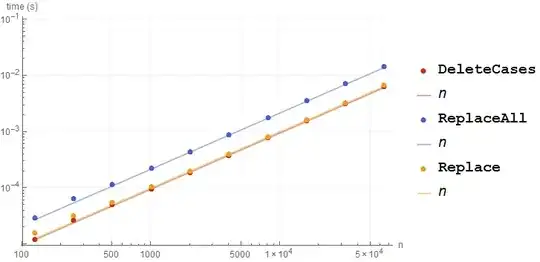
This shows that DeleteCases has only the slightest performance margin over {x_, x_} :> Sequence[] when the latter is used with a targeted levelspec, which I find somewhat surprising as I assumed the latter would incur additional evaluation.
DeleteCases:DeleteCases[%, {$x_, $x_}]– kale Aug 05 '14 at 13:22$x_a pattern ? I should learn that type of syntax :) – Mammouth Aug 05 '14 at 13:26xso that the first and last elements in the lists had to be the same. I usually add a$so I don't get confused if anotherxhas already been defined in my current context. – kale Aug 05 '14 at 13:31FindRoot:$x /. FindRoot[Exp[$x]==5, {$x,1}]. Like I said, complete personal preference. – kale Aug 05 '14 at 14:24