I want to multiply 1000by1000 matrices but MMA runs out of RAM.
LaunchKernels[]
dim = 1000;(*dimension of the matrices. There is 1000 of these 1000by1000 matrices*)
v = Developer`ToPackedArray[
Table[{
Table[
N@(KroneckerDelta[i, j] + Sin[i*j])
, {j, 1, dim}]}
, {i, 1, dim}]];(* The matrices themselves.*)
Developer`ToPackedArray[
ParallelSum[
Cos[i*k]*(v[[k]]\[Transpose].v[[i]] + v[[i]]\[Transpose].v[[k]])
, {i, 1, dim}, {k, 1, dim}]];(*Multiplication part and summation*)
Here is a snapshot of task manager. I ran the code then killed the kernels:
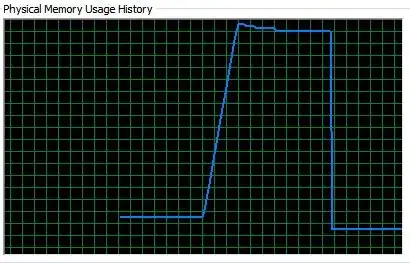
How can I improve this code. The problem is MMA uses a lot of RAM. I even used packed array but it didn't help. I know that in the summation part I am summing the transpose of the multiplied matrices and I could not to do the multiplication for the second term.
I edited the question to reflect the real problem better.
I used $HistoryLength = 0;, it didn't help.
Edit2
I want to see the effect of using packed arrays so I changed the dimension of the matrices and calculated the maximum used memory in the process of evaluation of those multiplications. For packed arrays I used:
v[dim_] :=
Developer`ToPackedArray[
Table[{Table[N@(KroneckerDelta[i, j] + Sin[i*j]), {j, 1, dim}]}, {i,
1, dim}]];(*The matrices themselves.*)
m1 = MaxMemoryUsed[]/N[10^6]
res = Table[{MaxMemoryUsed[]/N[10^6] - m1,
Developer`ToPackedArray[
Table[Cos[1.0*i*k]*(v[dim][[k]]\[Transpose].v[dim][[i]]), {i, 1,
dim}, {k, 1, dim}]];}, {dim, 28, 40}](* I removed the addition to the transpose in contrast to the code provided in the above*)
axis = Table[i, {i, 28, 40}];
ListPlot[
Join[{axis}\[Transpose], {Cases[Flatten[res], _Real]}\[Transpose], 2],
PlotMarkers -> {\[FilledCircle], 15},
PlotStyle -> Red,
Frame -> True,
FrameLabel -> {Style["Dimension", Bold, FontSize -> 15], Style["MaxMemoryUsed", Bold, FontSize -> 15]},
FrameStyle -> Directive[Black, Bold, 20]]
Here is the result:
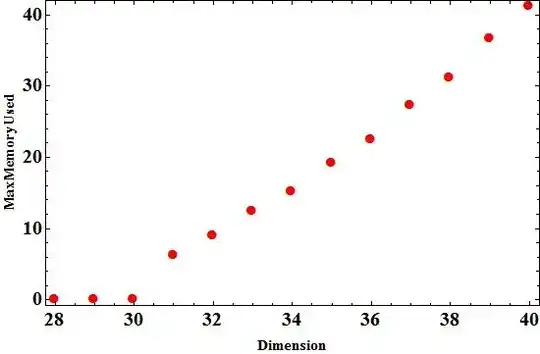
and here the result for the case I did not use packed arrays. After I got the result for packed arrays, I restart kernels.
v2[dim_] :=
Table[{Table[N@(KroneckerDelta[i, j] + Sin[i*j]), {j, 1, dim}]}, {i,
1, dim}];
m1 = MaxMemoryUsed[]/N[10^6]
res2 = Table[{MaxMemoryUsed[]/N[10^6] - m1,
Table[Cos[i*k]*(v2[dim][[k]]\[Transpose].v2[dim][[i]]), {i, 1,
dim}, {k, 1, dim}];}, {dim, 28, 40}]
axis = Table[i, {i, 28, 40}];
ListPlot[Join[{axis}\[Transpose], {Cases[
Flatten[res2], _Real]}\[Transpose], 2],
PlotMarkers -> {\[FilledCircle], 15}, PlotStyle -> Blue,
Frame -> True,
FrameLabel -> {Style["Dimension", Bold, FontSize -> 15],
Style["MaxMemoryUsed", Bold, FontSize -> 15]},
FrameStyle -> Directive[Black, Bold, 20]]
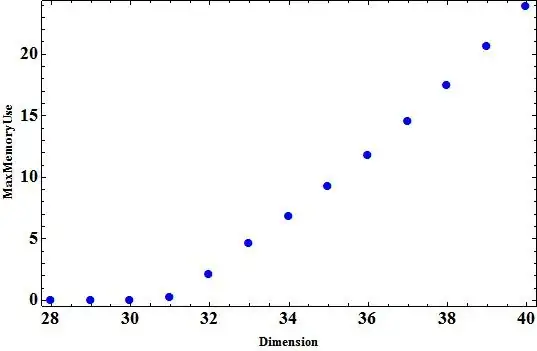
It seems using packed arrays is not memory efficient temporary. Can anybody reproduce these results?
SparseArrayshould be considered. You can work with those just like with any other matrix. – Yves Klett Nov 07 '14 at 12:18ParallelSum), first of all you need distribute definition of variables in parallel kernels withSetSharedVariables– molekyla777 Nov 07 '14 at 12:25t = Total[v]; u = Transpose[t].t; result = u + Transpose[u];will give the same result in a fraction of the time. – Simon Woods Nov 07 '14 at 13:01SetSharedvariabledoes not distribute definitions, it has a completely different purpose.DistributeDefinitionsis used for distributing definitions but since Mathematica 8 this happens automatically when usingParallelSum. – Szabolcs Nov 07 '14 at 14:44w = First@Transpose[v]; f = Array[Cos[#1 #2] &, {dim, dim}]; u = Transpose[w].f.w; result = u + Transpose[u];– Simon Woods Nov 07 '14 at 15:18Dotis super-optimised for packed arrays, far far quicker than the equivalent number of arithmetic operations. I expect @ybeltukov or @Szabolcs could give a more knowledgeable explanation. – Simon Woods Nov 07 '14 at 17:33