The "captive" mode seems unsupported (at least on Linux?), which is sadly not stated anywhere I looked.
So I've run into this same issue, thinking "captive" foreground tests would have full priority and available bandwidth and thus finish faster. But that seems not to be the case. So the smartctl manpage is misleading.
As part of a captive self-test, the smartctl process keeps waiting for the drive to finish and return. However, the SATA subsystem detects this outstanding command as a hang of the drive, and aborts after /sys/block/<blockdev>/device/timeout seconds have passed.
dmesg will log the drive reset (in my instance hanging off of an Adaptec controller),
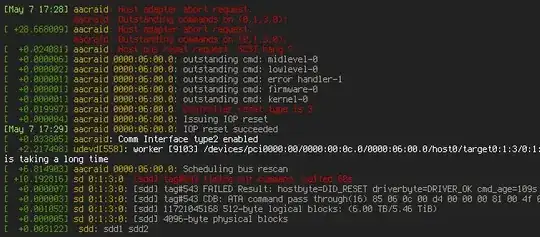
[May 7 17:28] aacraid: Host adapter abort request.
aacraid: Outstanding commands on (0,1,3,0):
[ +28.668009] aacraid: Host adapter abort request.
aacraid: Outstanding commands on (0,1,3,0):
[ +0.024081] aacraid: Host bus reset request. SCSI hang ?
[ +0.000006] aacraid 0000:06:00.0: outstanding cmd: midlevel-0
[ +0.000002] aacraid 0000:06:00.0: outstanding cmd: lowlevel-0
[ +0.000001] aacraid 0000:06:00.0: outstanding cmd: error handler-1
[ +0.000001] aacraid 0000:06:00.0: outstanding cmd: firmware-0
[ +0.000001] aacraid 0000:06:00.0: outstanding cmd: kernel-0
[ +0.019997] aacraid 0000:06:00.0: Controller reset type is 3
[ +0.000004] aacraid 0000:06:00.0: Issuing IOP reset
[May 7 17:29] aacraid 0000:06:00.0: IOP reset succeeded
[ +0.033805] aacraid: Comm Interface type2 enabled
[ +2.217498] udevd[558]: worker [9103] /devices/pci0000:00/0000:00:0c.0/0000:06:00.0/host0/target0:1:3/0:1:3:0/block/sdd is taking a long time
[ +6.814903] aacraid 0000:06:00.0: Scheduling bus rescan
[ +10.192816] sd 0:1:3:0: [sdd] tag#543 timing out command, waited 60s
[ +0.000007] sd 0:1:3:0: [sdd] tag#543 FAILED Result: hostbyte=DID_RESET driverbyte=DRIVER_OK cmd_age=109s
[ +0.000003] sd 0:1:3:0: [sdd] tag#543 CDB: ATA command pass through(16) 85 06 0c 00 d4 00 00 00 81 00 4f 00 c2 00 b0 00
[ +0.001052] sd 0:1:3:0: [sdd] 11721045168 512-byte logical blocks: (6.00 TB/5.46 TiB)
[ +0.000005] sd 0:1:3:0: [sdd] 4096-byte physical blocks
[ +0.003122] sdd: sdd1 sdd2
and the drive then logs a failed selftest:
SMART Extended Self-test Log Version: 1 (1 sectors)
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short captive Interrupted (host reset) 50% 196 -
The ticket describing this issue with smartmontools has been marked as "wontfix": https://www.smartmontools.org/ticket/1153
I don't think increasing the block device timeout is a solution for an extended selftest.
So we can't run captive tests, I guess. (Perhaps it's different for native SCSI drives?)

-Coption (i.e. that seems contradictory to your stated goal of not "taking the drive offline", and the root cause of your problem)? – sawdust Feb 25 '20 at 01:23