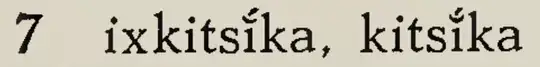\documentclass{article}
\usepackage{fontspec}
\setmainfont{Noto Serif}
\usepackage{multicol}
\newcommand\BFmapsto[2]{%
\noindent #1 $\mapsto$ {#2}\par
}
\ExplSyntaxOn
\cs_generate_variant:Nn
\seq_gset_split:Nnn
{ cno }
\cs_generate_variant:Nn
\tl_count_tokens:n
{ V }
\cs_generate_variant:Nn
\tl_greplace_all:Nnn
{ Nxx }
\int_new:N
\l_fc_rweqz_int
\int_new:N
\l_fc_rweqy_int
%------------------
\cs_set:Npn \fc_funcshowmap:n #1 {
% 1=translit pair from;to
\seq_set_split:Nnn
\l_fc_rweqz_seq
{ ; }
{ #1 }
\tl_set:Nx
\l_fc_rweqz_tl %from
{
\seq_item:Nn
\l_fc_rweqz_seq
{1}
}
\tl_set:Nx
\l_fc_rweqy_tl %to
{
\seq_item:Nn
\l_fc_rweqz_seq
{2}
}
\BFmapsto {\l_fc_rweqz_tl} {\l_fc_rweqy_tl}
}
%------------------
\cs_set:Npn \fc_functranslit:n #1 {
% 1=translit pair from;to
\seq_set_split:Nnn
\l_fc_rweqz_seq
{ ; }
{ #1 }
% \seq_show:c
% { l_fc_rweqz_seq }
\tl_set:Nx
\l_fc_rweqz_tl %from
{
\seq_item:Nn
\l_fc_rweqz_seq
{1}
}
% \tl_show:N
% \l_fc_rweqz_tl %from
\tl_set:Nx
\l_fc_rweqy_tl %to
{
\seq_item:Nn
\l_fc_rweqz_seq
{2}
}
\tl_greplace_all:Nxx
\g_myBFts_tl
{ \l_fc_rweqz_tl }
{ \l_fc_rweqy_tl }
% \tl_show:N
% \g_myBFts_tl
}
%------------------
\cs_set:Npn \ic_funcsortseq:cn #1#2 { % 1=seq, 2=order (<:descending, >:ascending)
\seq_sort:cn { #1 } %\l_fc_rweq_seq
{
\seq_clear:N
\l_fc_rweqz_seq
\seq_clear:N
\l_fc_rweqy_seq
\seq_set_split:Nnn
\l_fc_rweqz_seq
{ ; }
{ ##1 }
\seq_set_split:Nnn
\l_fc_rweqy_seq
{ ; }
{ ##2 }
\tl_set:Nx
\l_fc_rweqz_tl
{
\seq_item:Nn
\l_fc_rweqz_seq
{1}
}
\tl_set:Nx
\l_fc_rweqy_tl
{
\seq_item:Nn
\l_fc_rweqy_seq
{1}
}
\int_set:Nn
\l_fc_rweqz_int
{
\tl_count_tokens:V
\l_fc_rweqz_tl
}
\int_set:Nn
\l_fc_rweqy_int
{
\tl_count_tokens:V
\l_fc_rweqy_tl
}
\int_compare:nNnTF
{ \l_fc_rweqz_int } { #2 } { \l_fc_rweqy_int }
{ \sort_return_swapped: }
{ \sort_return_same: }
}
}
%------------------
\cs_set:Npn \doBFshowmap:n #1 {
\exp_args:Nx
\seq_map_function:cN
{ g_fc_rwe \g_fc_namespace_tl #1 _seq }
\fc_funcshowmap:n
}
%------------------
\cs_set:Npn \doBFtransts:n #1 {
% \seq_show:c
% { g_fc_rwe \g_fc_namespace_tl #1 _seq }
\exp_args:Nx
\seq_map_function:cN
{ g_fc_rwe \g_fc_namespace_tl #1 _seq }
\fc_functranslit:n
}
%--------------------
\NewDocumentCommand { \mfsloadaseq } { o m +m } {
% 1=namespace
% 2=seq name
% 3=data
\IfNoValueTF { #1 }
{ \tl_clear:N \g_fc_namespace_tl }
{ \tl_gset:Nn \g_fc_namespace_tl { #1 } }
\cs_if_free:cT
{ g_fc_rwe \g_fc_namespace_tl #2 _seq }
{ \seq_new:c
{ g_fc_rwe \g_fc_namespace_tl #2 _seq }
}
\seq_gclear:c
{ g_fc_rwe \g_fc_namespace_tl #2 _seq }
\seq_gset_split:cno
{ g_fc_rwe \g_fc_namespace_tl #2 _seq }
{ , }
{ #3 }
}
%--------------------
\NewDocumentCommand { \mfssortaseq } { o m m } {
%1=namespace
%2=seqname,
%3=><, asc/desc
\IfNoValueTF { #1 }
{ \tl_clear:N \g_fc_namespace_tl }
{ \tl_gset:Nn \g_fc_namespace_tl { #1 } }
\ic_funcsortseq:cn { g_fc_rwe \g_fc_namespace_tl #2 _seq } { #3 }
}
\NewDocumentCommand { \blackfoot } { m } {%
\BFtrans {#1}
}
\NewDocumentCommand { \BFtrans } { O{ts} m } {%
\cs:w BFtrans#1 \cs_end: {#2}
}
\tl_new:N \l_myBFts_tl
\NewDocumentCommand { \BFts } { m } { \BFtransts {#1} }
\NewDocumentCommand { \BFtransts } { m } {%
\tl_gset:Nn \g_myBFts_tl { #1 }
\doBFtransts:n {BF}
\tl_use:N \g_myBFts_tl
}
\NewDocumentCommand { \BFmap } { } {%
%\tl_gset:Nn \g_myBFts_tl { #1 }
\doBFshowmap:n {BF}
%\tl_use:N \g_myBFts_tl
}
\ExplSyntaxOff
%%%%%%
\mfsloadaseq{BF}{
a';á
,e';é
,i';í
,ib';ĭ́
,o';ó
,a;á
,e;é
,i;í
,i;ĭ́
,o;ó
,-;́
,--;̆́
}
\mfssortaseq{BF}{<}
\begin{document}
\blackfoot{ni'so}
\blackfoot{a' e' i' ib' o'} :: \blackfoot{a* e* i* i** o} :: \blackfoot{A- E-* I-* I--* O-* A-*a}
\noindent Transliteration Schemes
\begin{multicols}{4}
\BFmap
\end{multicols}
\bigskip
\begin{tabular}{cl}
1 & \blackfoot{nito'kska, nise'a}\
2 & \blackfoot{na'toka} \
3 & \blackfoot{niuo'kska, niuo'ka} \
4 & \blackfoot{nisoo', niso', ni'so} \
5 & \blackfoot{nisito', ni'sito} \
6 & \blackfoot{na'u} \
7 & \blackfoot{ixkitsib'ka, kitsib'ka} \
8 & \blackfoot{na'niso} \
9 & \blackfoot{pi'xkso} \
10 & \blackfoot{ke'po} \
100 & \blackfoot{kiipi'ppo} \
\end{tabular}
\end{document}