I just so happen to have a 4GB data file laying around, so I thought I might give this a try. My data file has one floating point number per line and the number of lines is
wc -l datafile.dat
264627000 datafile.dat
so a good 264 million data points. Trying to Import it,
temp = Import["datafile.dat"];
takes longer than it took to clean my office so I quit that.
Using ReadList at least worked,
temp = ReadList["datafile.dat"]; // AbsoluteTiming
(*{881.782, Null}*)
but it took almost 15 minutes and MemoryInUse[] returned 6393810904. Just trying to do a histogram on the data
hlist = HistogramList[temp]; // AbsoluteTiming
took all of my 8GB of RAM and eventually crashed the kernel. Using Sjoerd's answer method I was able to generate the list of bins and bincounts much faster than the read-and-bin method I outline below, but on my data and my machine it took a very long time and used up so much RAM that my machine wasn't usable. That brings up the point that sometimes you may want to generate a histogram on a data set so large that you could not hold it all in memory at one time.
So what we want to do is to create a histogram of data in a large file. I think it is necessary to know the bins you are going to use. Below, I am assuming that we know the max, min, and number of data points.
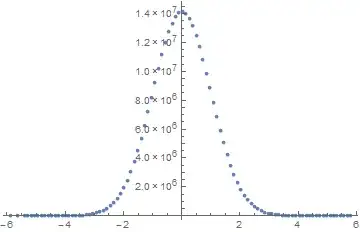
I'll work with a file that is ~500MB, that I created using this code, but this should work no matter the file size. This file has 30 million numbers in a tab-separated format. Since the size of the set is managable, here is what the result of the Histogram command looks like,
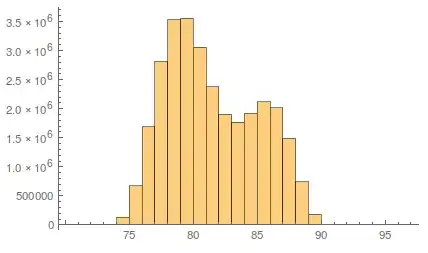
Let's try to reproduce this.
Now I open the file as a Stream,
file = OpenRead["datafile_medium.dat"];
Taking a cue from george2079's answer, we will read in the list in chunks. My data is an even multiple of 10,000, so I will use this as the block size.
You want to have the bins preconfigured, and all you need to do this is have the values of {max, min, ndata} and use Sturges' formula to determine the number of bins.
bins = Subdivide[min, max, Ceiling[Log[2, ndata] + 1]];
bincounts = ConstantArray[0, Length@bins - 1];
blocksize = 10000;
Monitor[
Do[
bincounts += BinCounts[
ReadList[file, Number, blocksize]
, {bins}];
, {n, Ceiling[ ndata/blocksize]}]; // AbsoluteTiming
, n]
For 30 million data points this took only 60 seconds.
Now to make the histogram. I made a histogram function, that takes a list of bins and the bincounts as arguments, by modifying Simon's answer here
histogram[{bins_, bincounts_}, plotopts : OptionsPattern[]] :=
Module[
{width = First@Differences@bins},
Graphics[{EdgeForm[Black], ColorData[97][8],
Rectangle[{#1 - 0.5 width, 0}, {#1 + 0.5 width, #2}] & @@@
Transpose[{Mean /@ (Partition[bins, 2, 1]), bincounts}]},
plotopts, Frame -> True, AspectRatio -> 0.7
]
];
histogram[{bins, bincounts}, BaseStyle -> 15, ImageSize -> 500,
FrameLabel -> {"value", "frequency"}]
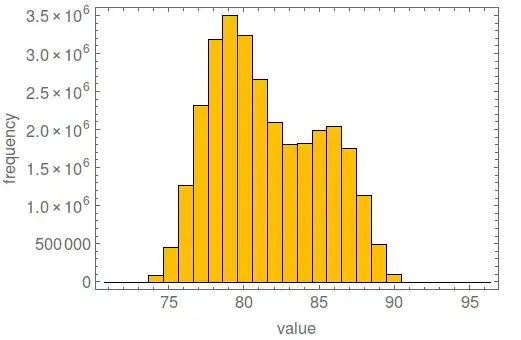
(anyone know what that default histogram color is?)
I was able to read in my 4GB file using this method in less than 9 minutes and bin the data, less time than reading the data in and storing it to a variable.
This method should work for arbitrarily large data sets, and the only requirement is that you know the bins ahead of time (or the range and the number of points).
Readnumber by number, generating a bin list for a histogram. (loose thought, haven't tried) – Kuba Jan 05 '16 at 13:54ReadListis much more efficient thanImport. Try it before you go to reading by chunks. – Szabolcs Jan 05 '16 at 13:55Histogram[data]or after theImportcommand? – Jason B. Jan 05 '16 at 13:59Importcommand. – a06e Jan 05 '16 at 14:03