I have hand-written 60 pixel times 60 pixel squares. I need to detect whether they are empty, x or circle. TextRecognize function fails. Is there some other function to process this kind of raster images with text?

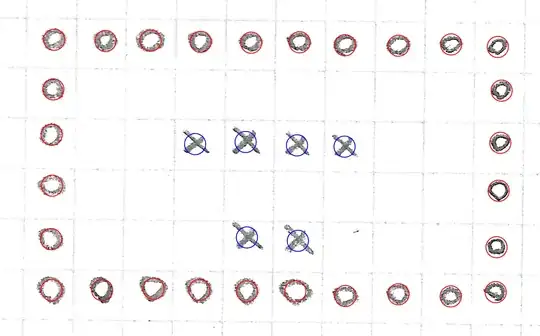
Circles: (0,0..9), (0..5,0), (0..5,9), (5,0..9)
Crosses: (2,3..6), (4,4..5)
Empty: (1,1..8), (2,1..2), (3,1..8), (4,1..3), (4,6..8)
I try to summarize and help people to solve the harder puzzle. Work in progress. Have fun!
I. Preprocessing (example)
1.1. thread about getting grid from raster image
<p>1.2. <a href="https://stackoverflow.com/questions/10196198/how-to-remove-convexity-defects-in-sudoku-square">convexity fix</a></p> <p>1.3. <a href="https://i.stack.imgur.com/kaWDq.png" rel="nofollow noreferrer">rotation</a></p>II. Testing
2.1. Further info about mathematical morphology and Mathematica's intro.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
ImageCorrelateandComponentMeasurementsmight be worth a try. – Niki Estner Apr 18 '13 at 19:10