There are two lists {a, b, c, a, d, a, e} and {a, c, a}. I need to remove those elements from the first list which appears in a second list, to get {b, d, a, e}
Asked
Active
Viewed 6,317 times
39
-
Related but not duplicate: (1290) – Mr.Wizard Jan 20 '13 at 10:28
11 Answers
24
New proposal
I was thinking about this problem today and came up with a new approach. In testing it appears to be competitively fast, often notably faster than any other method yet posted. It is also quite clean.
A limitation shared with rasher's uc: all elements in the drop list must be present in the main list.
fastRF[a_List, b_List] :=
Module[{c, o, x},
c = Join[b, a];
o = Ordering[c];
x = 1 - 2 UnitStep[-1 - Length[b] + o];
x = FoldList[Max[#, 0] + #2 &, x];
x[[o]] = x;
Pick[c, x, -1]
]
The question example:
fastRF[{a, b, c, a, d, a, e} , {a, c, a}]
{b, d, a, e}
Timings
The prior frontrunners for performance are Leonid's unsortedComplement and rasher's uc. I shall compare these to fastRF as well as my earlier removeFrom2. Here is a chart showing the performance of each function at removing a variable number of elements (second parameter) from a starting list of one million elements (first parameter). Timings performed in version 10.0.2.
Needs["GeneralUtilities`"]
one = RandomInteger[1*^5, 1*^6];
BenchmarkPlot[
{
removeFrom2[one, #] &,
unsortedComplement[one, #] &,
uc[one, #] &,
fastRF[one, #] &
},
RandomSample[one, #] &,
5^Range[8],
TimeConstraint -> 30
]

For all values (in this test) fastRF is indeed the fastest.
Explanation
The code above is quite opaque compared to my more direct and literal first answer. I think an explanation is in order.
The list of elements-to-remove, named b, is inserted at the beginning of main list, named a. Then the Ordering of this combined list is found. For the question example that looks like this, juxtaposed with the sorted list for illustration:
com = {a, c, a, a, b, c, a, d, a, e}
ord = Ordering[com]
com[[ord]]
{a, c, a, a, b, c, a, d, a, e}{1, 3, 4, 7, 9, 5, 2, 6, 8, 10}
{a, a, a, a, a, b, c, c, d, e}
1, 2, 3 in ord are the elements to drop, each along with a copy from the main list. For example 4 and 7 should be dropped because of 1 and 3, and 6 should be dropped because of 2. To achieve this I first apply numeric transformations including UnitStep to turn the drop values to 1 and all others to -1. I then use FoldList for a modified accumulate process:
1 - 2 UnitStep[-1 - 3 + ord]
x = FoldList[Max[#, 0] + #2 &, %]
{1, 1, -1, -1, -1, -1, 1, -1, -1, -1}{1, 2, 1, 0, -1, -1, 1, 0, -1, -1}
Each -1 in the output is an element to keep; all others are elements to drop. I then need to put this list back into the original order of the combined list (com). I use the method Simon Woods posted in Sort two lists at the same time, based on another due to its superior performance. All that remains is to Pick the elements of com that correspond to the -1's in x:
x[[ord]] = x; x
Pick[com, x, -1]
{1, 1, 2, 1, -1, 0, 0, -1, -1, -1}{b, d, a, e}
-
-
@rasher Thank you. :-) By the way I tried dropping the length of
bfrom (final)xand picking fromabut it didn't seem faster, which surprised me. If you find another way to refine this please let me know. – Mr.Wizard Feb 21 '15 at 05:20 -
Doesn't work when the first list has duplicate elements:
lrg = {1, 2, 3, 2, 5, 6, 7}; sm = {3, 5, 2}; fastRF[lrg, sm] --> {1, 2, 6, 7}. Besides, I am surprised that this question was even having so many rather complex answers, given this answer of mine, which seems to be faster than any of these, up to hundreds of thousands of elements. Admittedly, this one came out later. Anyway, if you can make it work without making the code a lot more complex, or losing efficiency, you get my upvote. – Leonid Shifrin Feb 21 '15 at 12:56 -
@Leonid They are working you too hard my friend. :-O
{1, 2, 6, 7}is the desired result for that input. Have you forgotten your own answer here? And your own comment below the question? This question is not a duplicate of (1290) andDeleteCases[list1, Alternatives @@ list2]is not a solution. – Mr.Wizard Feb 21 '15 at 16:54 -
1@Mr.Wizard Oops. You are right. And I've been quite busy recently indeed, so it's not the first time I've been missing the point recently. Perhaps, time to take a break from SE. As to your code, it is quite clever. To make up for my blunder, I forced myself to understand it just by staring at it, without reading your explanation or trying anything out in Mathematica. Very nice! Of course, you got my vote. – Leonid Shifrin Feb 21 '15 at 17:38
-
@Leonid I hope you can take a nice vacation soon. So reading my code is a form of penance now, huh? :o) (Thank you.) – Mr.Wizard Feb 21 '15 at 17:42
-
@Mr.Wizard Re: vacation - unlikely to happen very soon, but thanks! Re: your code - no, but this isn't a trivial piece of code. I suspect it would be just as hard even if I wrote it myself and then looked at it after a while. I was only able to fully understand it by reading because I did use or see similar tricks before (but not in this combination and not for this problem, regretfully). It uses somewhat similar ideas as my code is using, but has a more clever and efficient way of constructing a mask to filter out elements from the first list. – Leonid Shifrin Feb 21 '15 at 17:47
-
With
short = RandomInteger[1*^5, 2*^4]andlong = RandomInteger[1*^5, 2*^5]defined in Mr.Wizard's answer withremoveFromandremoveFrom2,fastRF[long, short]gives a different result fromremoveFrom[long, short],removeFrom2[long, short], andunsortedComplement[long, short]. – Taiki Mar 08 '15 at 14:33 -
1@Taiki I believe you are experiencing the limitation that I mentioned in this answer. Every element in the drop list must be present in the main list, including sufficient copies of it. So for example
fastRF[{3, 1, 2}, {0, 1, 2}]will not work as intended. Neither willfastRF[{3, 1, 2}, {1, 1}]. If this circumstance cannot be prevented it is best to useunsortedComplementamong the methods posted at this time. – Mr.Wizard Mar 09 '15 at 00:38 -
22
Please see my second answer; the method therein is far more efficient than the ones below.
removeFrom[b_List, a_List] := Module[{f},
f[_] = 0;
(f[#] = -#2) & @@@ Tally[a];
Pick[b, UnitStep[f[#]++ & /@ b], 1]
]
removeFrom[{a, b, c, a, d, a, e}, {a, c, a}]
{b, d, a, e}
Here somewhat longer but also a bit more efficient:
removeFrom2[b_List, a_List] := Module[{f, g},
(f[#] = -#2) & @@@ Tally[a];
g[x_] /; f[x] < 0 := f[x]++;
g[_] = True;
Select[b, g]
]
This avoids incrementing counters for elements that will never be dropped.
With some data this is not too far behind Leonid's method:
short = RandomInteger[1*^5, 2*^4];
long = RandomInteger[1*^5, 2*^5];
unsortedComplement[long, short] // Short // Timing
removeFrom2[long, short] // Short // Timing
{0.202, {68819,45303,67901,31724,23958,11781,29518,20287,46528,<<183297>>,75098,80755,34879,14667,67114,86027,24796,95072,59695}}
{0.25, {68819,45303,67901,31724,23958,11781,29518,20287,46528,<<183297>>,75098,80755,34879,14667,67114,86027,24796,95072,59695}}
Where there is heavy duplication Leonid's method is still much faster than mine.
Mr.Wizard
- 271,378
- 34
- 587
- 1,371
-
Good work. I tried something along these lines but failed to make it simple. This is about 5 times slower than mine for the large lists I tried, but pretty fast for its code size. +1. – Leonid Shifrin Jan 20 '13 at 10:48
-
@Leonid Thanks. As usual we bring different things to the table. I'm still trying to understand yours... – Mr.Wizard Jan 20 '13 at 10:49
-
1Read the explanation on the page I linked to, it is pretty detailed. – Leonid Shifrin Jan 20 '13 at 10:50
-
1Your solution has a potentially better complexity than mine (linear in both lists), but is slowed down by the hash lookup constant,and, more importantly, multiple assignments / hash modifications you perform at run-time. So, the larger the lists, the more your solution is favored. Theoretically, for some large lists, it should become faster than mine. In practice, the lists should probably be very large to observe that. – Leonid Shifrin Jan 20 '13 at 10:52
-
@Leonid I always value your analysis. Can you think of a way to make this method faster? – Mr.Wizard Jan 20 '13 at 10:57
-
Nothing comes to mind at the moment. I think it is naturally speed-bounded by the bottleneck associated with multiple
++operations on the hash. Short of sorting the lists (which is what I do), I don't see a way to avoid that. – Leonid Shifrin Jan 20 '13 at 11:03 -
Sorry, disregard my latest suggestion. This won't work since you really need a hash in your method. – Leonid Shifrin Jan 20 '13 at 11:05
-
It is interesting that the solutions to this problem posted so far fit exactly into the classification I used in my book in terms of efficiency, particularly here - with kguler's solution belonging to "scripting" layer, mine to "system" layer (well, more or less), and yours somewhere between "intermediate" and "system". All are useful, since they realize different compromise points between dev.time/complexity and performance. – Leonid Shifrin Jan 20 '13 at 11:20
-
@Leonid I found a way to make it a little faster; please take a look. – Mr.Wizard Jan 20 '13 at 13:35
-
@Leonid in the second method adding
g@_ = True;and usingSelect[b, g]tests a bit faster. Can you confirm that on v9? – Mr.Wizard Jan 20 '13 at 13:42 -
1Yes, I do confirm. But the main reason for why your code is speed-equivalent to mine in your new benchmark is that you used data with very little repetition (almost all elements are unique). When you use my benchmarks, you still see 5-7 times difference. So, your method is optimal for almost unique data. This is not to detract from your solution, of course. I find it quite interesting that you found such a fast one based on rules / hashes, somehow I did not expect this would be possible. – Leonid Shifrin Jan 20 '13 at 13:48
-
-
Just for completeness: the other class of cases where your code gets a bit slower is when almost all elements are deleted, even when there isn't much duplication, for example for
large1 = RandomInteger[100000, 10^5]; large2 = RandomInteger[10^5, 10^6];. – Leonid Shifrin Jan 20 '13 at 16:35 -
1
-
@Kuba Indeed. Thanks for pointing it out. Now the dilemma of what to do with late-discovered duplicates: how do I not deprecate your nice answer? I wish it were posted here instead. If you delete and repost you are unlikely to recover all your votes. How do you feel about a merge? You'd lose the Accept but keep the votes, and in time probably get greater exposure. – Mr.Wizard Feb 21 '15 at 07:51
-
@Mr.Wizard good question, deserves a meta post. I think this is quite common case but only few folks look for duplicates. Merge is quite tempting but what if some anwers are really a duplicate? You would have to merge it manually. I'd say marking a duplicate is enough and if there are anwers that deserve advertisement one could stress this in question edit or comments. Moreover, not here but sometimes both answers deserve an accept, one could have been brilliant at the time of V6 for example and new shows neat usage of V10 functions. Tough call. – Kuba Feb 21 '15 at 08:04
-
@Mr.Wizard This way is also more safe, you'd have to take a really close look at questions, sometimes they differ slightly enough to allow answers that are not applicable in other case. – Kuba Feb 21 '15 at 08:10
-
@Kuba In fact that is the case here; the new question permits answers that sort the result while this one does not. It would be inappropriate to move answers with a merge. However I still think the Close was appropriate. By the way have you seen my new method below? I am quite pleased with it. :-) – Mr.Wizard Feb 21 '15 at 08:22
-
@Mr.Wizard That's why I try to edit my answers if they are old. No one's scrolling to the bottom :) – Kuba Feb 21 '15 at 08:39
18
Implementation
I am sure I missed a more elegant / short version, but here is an implementation which will be efficient even for large lists:
Clear[unsortedComplement];
unsortedComplement[x_, y_] :=
Module[{order, xsorted, distinct, freqs, posintervals, freqrules},
xsorted = x[[order = Ordering[x]]];
{distinct, freqs} = Transpose[Tally[xsorted]];
freqrules = Dispatch[Append[Rule @@@ Tally[y], _ -> 0]];
posintervals =
Transpose[{
Most[#] + Replace[distinct, freqrules, {1}],
Rest[#] - 1
}] &[Prepend[Accumulate[freqs], 0] + 1];
x[[Sort@order[[Flatten[Range @@@ posintervals]]]]]]
It borrows main ideas from here, but modifies it to the needs of the problem at hand. Once position intervals for elements in the sorted main list are found, they are shrinked by the number of same elements present in the second list, from the start (from the left end). From this, I generate partial list of positions in the ordered list, and reverse that via the ordering of that list, to get a list of positions in the original list. The algorithm has a log-linear complexity in the length of the first list and linear complexity in the length of the second list.
Examples and benchmarks
We have
unsortedComplement[{a,b,c,a,d,a,e},sub = {a,c,a}]
(* {b,d,a,e} *)
for larger lists:
large1 = RandomInteger[1000,10^5];
large2 = RandomInteger[1000,10^4];
(res1=unsortedComplement[large1,large2])//Short//Timing
(* {0.078,{951,956,345,459,345,951,956,<<89986>>,443,977,568,340,496,887,946}} *)
(res2=Fold[Delete[#1,Position[#1,#2,1,1]]&,large1,large2])//Short//Timing
(* {35.,{951,956,345,459,345,951,956,<<89986>>,443,977,568,340,496,887,946}} *)
res1==res2
(* True *)
Leonid Shifrin
- 114,335
- 15
- 329
- 420
14
A much faster method. Based on my method for multiple-position finding:
uc[list_, eles_] := Module[{dt = Tally[eles], fm},
fm = findMultiPosXX[list, dt[[All, 1]]];
list[[Delete[Range@Length@list,
Transpose[{Flatten[MapThread[Take, {fm, dt[[All, 2]]}]]}]]]]]
Caveats: I assume the list of elements to be deleted is a subset of the target list. Easily modified if that's not the case.
A quick performance comparison with the two fasted methods posted previously. Relative performance (time, normalized to 1 for the fastest), on a list generated with RandomInteger[size,1000000]. Labels correspond to size of "unique" pool of the 1000000 elements and number of elements deleted ( 1/10%, 1%, and 10% for each size). Over this test set, the average advantage is about 9X faster than the fastest alternative of each set, ranging from about a 65% advantage to over 12000% :
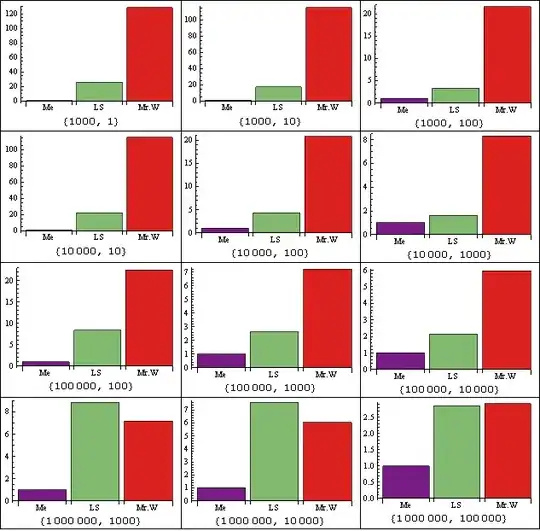
-
I haven't yet made the time to read and understand your recent series of related answers but the timings look very impressive. I do feel embarrassed for my answer now however. :-p – Mr.Wizard Apr 23 '14 at 08:08
-
Is
findMultiPoshere the same function asfindMultiPosXXin the linked post? – Mr.Wizard Apr 23 '14 at 08:11 -
@yep - (well, a shortened version). I'll edit to show "XX". Sounds meaner... Re: prior comment: LOL, your method(s) are slick, as usual, and I've been surprised at the effectiveness of the multi-position trick on several problems I'd been working on. – ciao Apr 23 '14 at 08:17
12
list1 = {a, b, c, a, d, a, e}; list2 = {a, c, a};
Fold[Delete[#1, Position[#1, #2, 1, 1]] &, list1, list2]
(* {b, d, a, e} *)
or
With[{patt = Table[Unique[], {Length[list2] + 1}]},
ReplaceAll[list1, Riffle[Pattern[#, BlankNullSequence[]] & /@ patt, list2] :> patt]]
(* {b, d, a, e} *)
kglr
- 394,356
- 18
- 477
- 896
7
Here's a slightly unconventional solution using patterns, and is very compact too:
{list1, list2} = {{a, c, a}, {a, b, c, a, d, a, e}};
Fold[# /. #2 &, list2, {h___, #, t___} :> {h, t} & /@ list1]
(* {b, d, a, e} *)
This exploits the fact that by default, BlankNullSequence[] seeks the Shortest sequence, thus you end up eating the occurrences from the left, as desired.
rm -rf
- 88,781
- 21
- 293
- 472
-
Surely clever, but also very slow. Can you think of a way to make this faster? Something to keep the list from being rescanned so many times? – Mr.Wizard Jan 20 '13 at 16:55
-
Nevertheless this appears to be faster than the more obvious
Positionmethod so +1. – Mr.Wizard Jan 20 '13 at 17:01 -
1Heh, replacements with
___is never going to beat/come close to a solution like yours/Leonid's :) But yes, it's quite a bit faster than thePositionapproach... I can't think of ways to speed it up right now. At least, not without significantly altering the simplicity of the above solution (maybe there is a way and I'm just being thick...) – rm -rf Jan 20 '13 at 20:06 -
I'm surprised that
Positionis slower (it is, I ran it on my computer -- quite a bit slower). Any thoughts on why it is slow? – Mike Honeychurch Jan 20 '13 at 21:16 -
@MikeHoneychurch I'm not entirely sure (Leonid would be the one to ask), but if I had to guess, I'd wager that it's because pattern matching is performed at a much lower level (i.e., not in the main evaluation loop) than
Position, thus reducing some of the overhead. – rm -rf Jan 21 '13 at 17:25 -
@rm-rf Without going too deep into this, I'd think you are right. The funny thing is, I wasn't notified of your comment. – Leonid Shifrin Jan 21 '13 at 17:26
-
@LeonidShifrin Whoa, are you psychic? You weren't notified because I didn't ping you (it was less than a minute ago). I was just hovering over your answer, getting ready to ping you to take a look at my explanation! O_o – rm -rf Jan 21 '13 at 17:28
-
@rm-rf I am,sometimes :) I was staring at your answer and comments for it for about 2 minutes when I saw your comment popping up. And I switched to it completely randomly from something else I was doing, not on SE. – Leonid Shifrin Jan 21 '13 at 17:29
6
In Mathematica 9.0.0 there are several undocumented functions for dealing with hash maps explicitly.
Language`HashMap[key1->val1, key2->val2, ...]creates new hash map from rulesLanguage`HashMapAssociate[hmap, key, value]adds new key/value pairLanguage`HashMapLookup[hmap, key]returns value associated with a key
Here is the solution based on these functions:
remover[long_List, short_List] := Module[{hmap, lookupresult},
hmap = Language`HashMap@@Apply[Rule, Tally[short], {1}];
Select[long, (lookupresult = Language`HashMapLookup[hmap, #];
Or[lookupresult === $Failed, lookupresult === 0,
(hmap = Language`HashMapAssociate[hmap, #, lookupresult - 1]; False)]) &]
]
But for this particular question solutions by Leonid and Mr.Wizard are faster.
Nick Stranniy
- 1,233
- 9
- 15
3
Dirty and slow...
v1 = {a, b, c, a, d, a, e};
v2 = {a, c, a};
Flatten[Table @@@ Fold[Function[{list, ele},
If[#1 === ele, {#1, If[#2 - 1 >= 0, #2 - 1, 0]}, {#1, #2}] & @@@ list], Tally[v1], v2]]
{a,b,d,e}
yode
- 26,686
- 4
- 62
- 167
-
Can you elaborate on 'very fast'? I run Mr.Wizard's benchmark with your code and this is what I get: https://i.stack.imgur.com/fgUh2.png – Kuba Dec 13 '17 at 09:59
-
1
3
DeleteElements(since V 13.1) makes this rather complicated problem surprisingly simple:
list = {a, b, c, a, d, a, e};
remove = {a, c, a};
Remove up to 2 instances of a and up to 1 instance of c
rule = Rule @@ Reverse @ Transpose @ Tally @ remove
{2, 1} -> {a, c}
DeleteElements[list, rule]
{b, d, a, e}
Addendum
Like kglr proposed in his comment we can skip the definition of rule and simply write:
DeleteElements[list, 1 -> remove]
eldo
- 67,911
- 5
- 60
- 168
2
The positions of the elements to be deleted:
pos = Catenate@MapThread[Take[#1, #2] &, {Lookup[PositionIndex[list], Union@#],
Values[Counts[#]]}] &@remove;
Then, using Replacepart:
ReplacePart[list, Thread[pos -> Nothing]]
({b, d, a, e})
A variant of @eldo's solution using Counts is the following:
rule = Rule @@ {Values[#], Keys[#]} &@Counts[remove]
DeleteElements[list, rule]
({b, d, a, e})
E. Chan-López
- 23,117
- 3
- 21
- 44
1
An approach using Reap and Sow avoiding rescanning list.
Simple Approach where order does not matter
simple[h_, p_] :=
Join @@ (Table[#[[1]], {#[[2]]}] & /@
Cases[Last@
Reap[Sow[1, #] & /@ h; Sow[-1, #] & /@ p, _, {#1, Total@#2} &],
Except[{_, 0}]])
For the test case this yields:
{a, b, d, e}
Perhaps, not the desired outcome.
Order matters
This is somewhat messy but I post anyway. Most of the code relates to order:
comp[x_, y_] := Module[{},
fun[q_] :=
If[Length[q] == 1, q,
Drop[#[[1]], Length[#[[2]]]] &@GatherBy[q, Sign]];
ls[u_, v_] :=
Cases[Last@
Reap[Join[Table[Sow[j, u[[j]]], {j, Length[u]}],
Table[Sow[-j, v[[j]]], {j, Length[v]}]], _, {#1, fun[#2]} &],
Except[{_, {}}]];
ord[u_] := Module[{pos, tab, or},
pos = Flatten@u[[All, 2]];
or = Thread[Sort[pos] -> Range[Length[pos]]];
tab = Table[1, {Length[pos]}];
ReplacePart[tab,
Flatten@(Thread[#[[2]] -> #[[1]]] & /@ (u /. or))]];
ord[ls[x, y]]]
For the test case this yields the desired:
{b, d, a, e}
ubpdqn
- 60,617
- 3
- 59
- 148